SQL 중심적인 개발의 문제점과 JPA 발생 배경에 대해 이해한다.
인프런 강의 참고
Goal
- SQL에 의존적인 개발을 하게 된 배경
- SQL 중심적인 개발의 문제점
- 지루한 코드의 무한 반복
- 객체 지향과 관계형 데이터베이스 간의 패러다임 불일치
- 객체(Object)와 관계형 데이터베이스(RDB)의 차이
- 모델링 과정에서의 문제
- 객체 그래프 탐색에서의 문제
- “비교하기” 에서의 차이
배경
- JPA와 모던 자바 데이터 저장 기술
- 애플리케이션 객체 지향 언어 (Java, Scala 등) + 관계형 DB (Oracle, MySQL 등)
- 객체를 영구 보관하는 다양한 저장소 (RDB, NoSQL, File, OODB 등) 가 존재하지만 현실적인 대안은 관계형 DB다.
- 즉, 객체를 관계형 DB에 저장해서 관리하는 것이 중요하다.
- 관계형 DB를 사용하려면 SQL을 짤 수 밖에 없다.
- 관계형 DB를 쓰는 상황에서는 SQL에 의존적인 개발을 피하기 어렵다.
- 하지만! SQL 중심적인 개발에는 여러 문제점이 있다.
SQL 중심적인 개발의 문제점
1. 지루한 코드의 무한 반복
- CRUD의 반복
- 자바 객체를 SQL로, SQL을 자바 객체로 변환하는 과정의 반복
- Ex)
- 회원에 나이 정보를 추가하고자 한다.
- Member 클래스에
private int age'를 추가한다. - INSERT, SELECT, UPDATE 등 관련된 모든 쿼리에 age 정보를 추가한다.
2. 객체 지향과 관계형 데이터베이스 간의 패러다임 불일치
- 객체 지향
- ‘객체 지향 프로그래밍은 추상화, 캡슐화, 정보은닉, 상속, 다형성 등 시스템의 복잡성을 제어할 수 있는 다양한 장치들을 제공한다.’ - 어느 객체지향 개발자
- 필드와 메서드 등을 묶어서 잘 캡슐화해서 사용하는 것이 목표
- 관계형 데이터베이스 (RDB)
- 데이터를 잘 정규화해서 보관하는 것이 목표
- 패러다임이 다른 두 가지를 가지고 억지로 매핑하기 때문에 여러 가지 문제가 발생한다.
- Object를 RDB에 넣으려고 하니까 문제가 발생한다.
- 하지만, RDB가 인식할 수 있는 것은 SQL뿐이기 때문에 결국, Object를 SQL로 짜야한다.
- Object -> [SQL 변환] -> RDB에 저장
- [개발자 == SQL 매퍼] 라고 할만큼 SQL 작업을 너무 많이 하고 있다.
3. 객체(Object)와 관계형 데이터베이스(RDB)의 차이
1) 상속
- Object
- 상속 관계가 있다.
- RDB
- 상속 관계가 없다.
- Object의 상속 관계와 유사한 물리 모델로, Table 슈퍼타입-서브타입 관계가 존재한다.
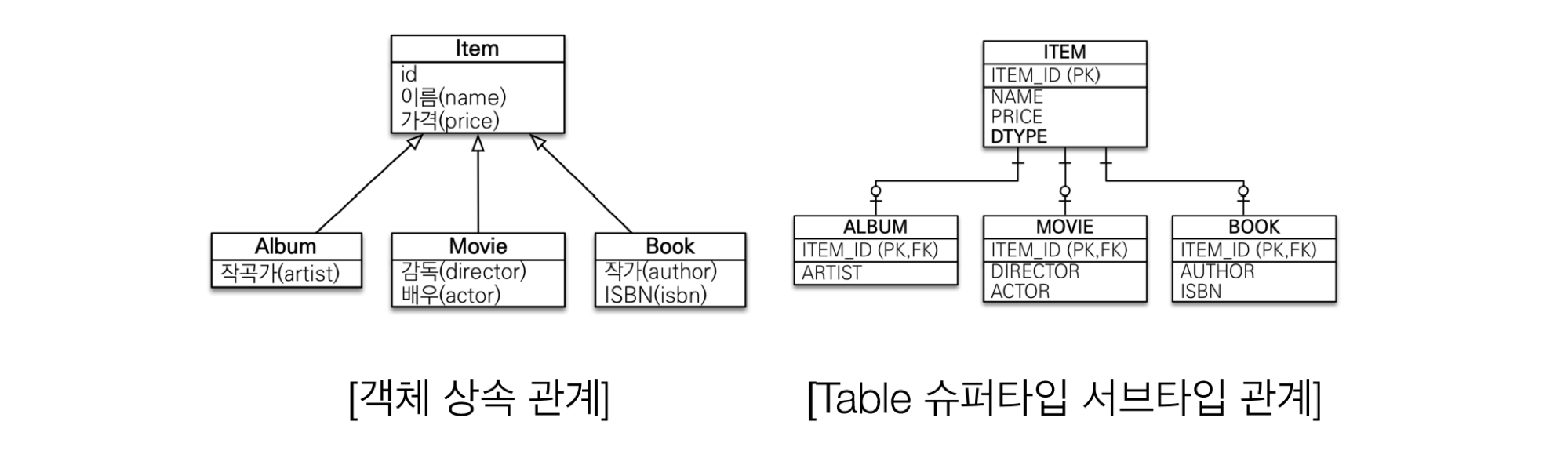
- Album 객체를 DB에 저장하는 과정
- 객체를 분해한다. (Album 객체는 Item의 속성을 모두 가짐)
- 각각 다른 테이블에 대한 INSERT 쿼리를 두 번 날린다.
INSERT INTO ITEM ...INSERT INTO ALBUM ...
- Album 을 조회하는 과정 (문제!!!)
- 각각의 테이블에 따른 Join SQL을 작성한다.
- Item과 Album을 Join해서 데이터를 가져온다.
- 각각의 객체를 생성하고 모든 필드값을 세팅한다.
- Item과 Album 각각 모든 필드값을 세팅한다.
- Movie, Book을 조회하고 싶으면 위의 과정을 또 반복해야 한다…
- 그래서! DB에 저장할 객체에는 상속 관계를 사용하지 않는다.
- 각각의 테이블에 따른 Join SQL을 작성한다.
- 자바 컬렉션에 저장하면?
- 저장:
list.add(album); - 조회:
Album album = list.get(albumId); - 다형성 활용:
Item item = list.get(albumId);- 심지어 객체 세상이기 때문에 필요하면 부모 타입으로 조회한 후 다형성으로 활용할 수도 있다.
- 저장:
- 자바 컬렉션에 저장하면 굉장히 단순한 작업이 관계형 데이터베이스에 넣고 빼는 순간, 중간 중간의 Object와 RDB의 매핑 작업을 개발자가 직접 해줘야 하기 때문에 굉장히 번잡한 일이 된다.
2) 연관 관계
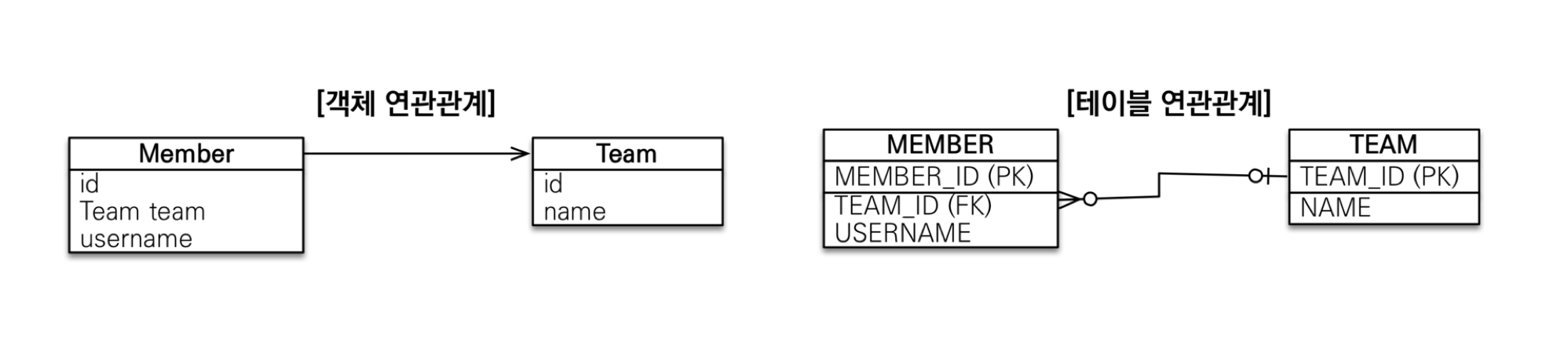
- Object
- 참조(Reference)를 사용하여 연관 관계를 찾는다.
- Ex)
member.getTeam();
- Ex)
- 단방향으로만 관계가 존재한다.
- Member -> Team은 가능하지만, Team -> Member는 불가능하다.
- 참조(Reference)를 사용하여 연관 관계를 찾는다.
- RDB
- 외래키(FK)를 사용하여 Join 쿼리를 통해 연관 관계를 찾는다.
- Ex)
JOIN ON M.TEAM_ID = T.TEAM_ID
- Ex)
- 양방향으로 모두 조회가 가능하다. 즉, 단방향이 존재하지 않는다.
- Member -> Team 가능: MEMBER.TEAM_ID(FK)와 TEAM.ID(PK)를 Join
- Team -> Member 가능: TEAM.ID(PK)와 MEMBER.TEAM_ID(FK)를 Join
- 외래키(FK)를 사용하여 Join 쿼리를 통해 연관 관계를 찾는다.
3) 데이터 타입
4) 데이터 식별 방법
4. 모델링 과정에서의 문제
# 객체를 테이블에 맞추어 모델링
class Member {
String id; // MEMBER_ID 컬럼 사용
Long teamId; // TEAM_ID FK 컬럼 사용 //**
String username; // USERNAME 컬럼 사용
}
class Team {
Long id; // TEAM_ID PK 사용
String name; // NAME 컬럼 사용
}
- MEMBER.TEAM_ID에 해당하는 FK를 그대로 필드에 추가한다.
Long teamId;
- 이렇게 설계된 객체를 DB에 저장 하려면,
INSERT INTO MEMBER(MEMBER_ID, TEAM_ID, USERNAME) VALUES ...
- 문제!: 객체지향스럽지 않다.
- Team 객체의 참조값 자체가 필드에 들어가는 것이 더 객체지향스럽다고 할 수 있다.
# 객체다운 모델링
class Member {
String id; // MEMBER_ID 컬럼 사용
Team team; // 참조로 연관관계를 맺는다. //**
String username; // USERNAME 컬럼 사용
Team getTeam() {
return team;
}
}
class Team {
Long id; // TEAM_ID PK 사용
String name; // NAME 컬럼 사용
}
- Team 객체의 참조값 자체를 필드에 넣는다.
Team team;
- 이렇게 설계된 객체를 DB에 저장 하려면,
member.getTeam().getId()로 값을 얻어와 TEAM_ID에 넣는다.INSERT INTO MEMBER(MEMBER_ID, TEAM_ID, USERNAME) VALUES ...
- Member 객체를 조회 하려면,
- MEMBER와 TEAM을 Join해서 데이터를 한 번에 모두 가져온다.
- Member와 Team에 대한 값을 각각 모두 세팅한다.
member.setTeam(team);과 같이 직접 연관 관계를 맺어 준다.- 해당 member 객체를 반환한다.
- 문제!: 데이터 조회의 복잡성
SELECT M.*, T.* FROM MEMBER M JOIN TEAM T ON M.TEAM_ID = T.TEAM_IDpublic Member find(String memberId) { // SQL 실행 ... Member member = new Member(); // 데이터베이스에서 조회한 회원 관련 정보를 모두 입력 ... Team team = new Team(); // 데이터베이스에서 조회한 팀 관련 정보를 모두 입력 ... member.setTeam(team); // 회원과 팀 관계 설정 //** return member; } - 객체다운 모델링을 자바 컬렉션에 관리하면?
- 데이터 조회의 복잡성이 사라져, 좋은 설계가 된다.
- 저장
list.add(member);
- 조회
Member member = list.get(memberId);Team team = member.getTeam();
- 이런 모델링을 DB에 넣는 순간, 굉장히 복잡해지며 생산성(조회 복잡)이 나빠진다.
- 생산성이 높은 방법?
- Member, Team 을 모두 포함한 큰 클래스(Super DTO)를 하나 만든다.
- Super DTO 하나를 반환한다.
- 오히려 이런 방법이 생산성 측면에서는 좋은 방법일 수도 있다.
5. 객체 그래프 탐색에서의 문제
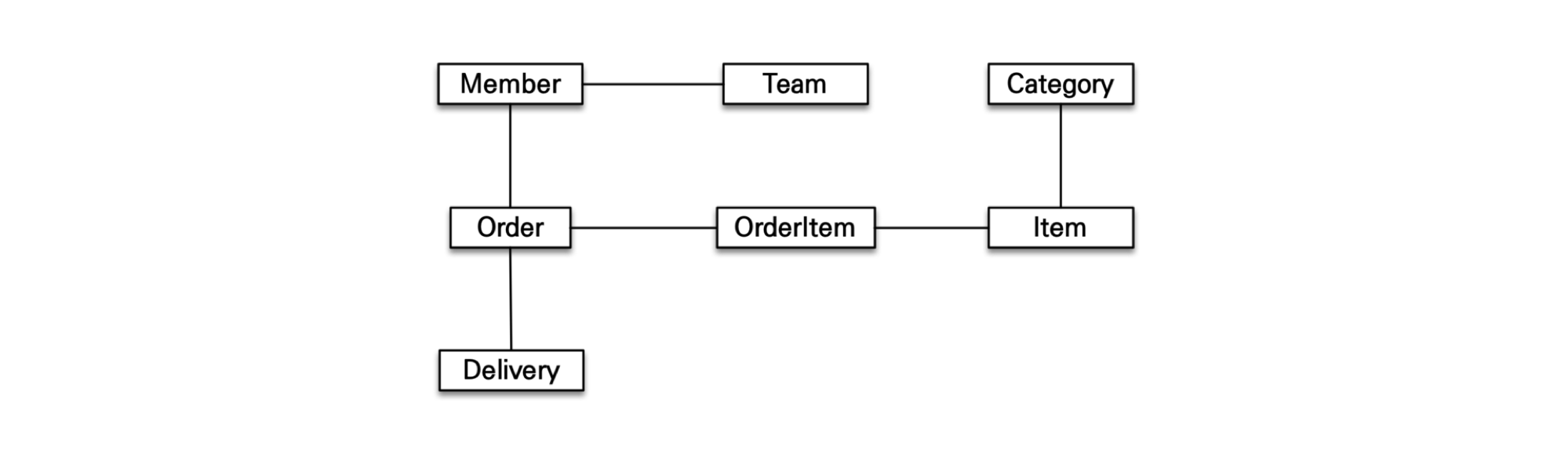
- 객체는 자유롭게 객체 그래프(연관 관계가 있는 객체 사이)를 탐색할 수 있어야 한다.
member.getTeam(),member.getOrder().getOrderItem()등 …
- 하지만, 서비스 로직에서 RDB와 연결된 데이터를 탐색할 때 객체 그래프를 탐색할 수 없다.
- Why? 처음 실행하는 SQL에 따라 탐색 범위가 결정되기 때문이다.
- Ex) 처음 SQL에서 Member와 Team을 가져왔다고 하면, Order는 가져오지 않았기 때문에
member.getOrder()는 null이 된다.SELECT M.*, T.* FROM MEMBER M JOIN TEAM T ON M.TEAM_ID = T.TEAM_IDmember.getTeam(); // OK member.getOrder(); // null
문제점
- 문제!: Entity 신뢰 문제
class MemberService { ... public void process() { Member member = memberDAO.find(memberId); member.getTeam(); // ??? member.getOrder().getDelivery(); // ??? } } - Ex) 개발자 A가 DAO를 구현하고 개발자 B가 위의 서비스 로직(
process())을 구현했을 때,- 개발자 B는 DAO에서 반환한 엔티티를 신뢰하고 사용할 수 없다.
- DAO에서 직접 어떤 쿼리를 날렸는지 확인하지 않는 이상, 알 수가 없다.
- 이와 같은 계층형 아키텍처(Layered 아키텍처)에서는 그 다음 계층에서 신뢰하고 사용해야 하는데, 여기에서는 엔티티를 신뢰할 수 없는 문제가 발생하게 된다.
- 물리적으로는 Service Layer, DAO Layer 등으로 계층이 분리되어 있지만,
- 논리적으로는 DAO 내부 코드를 직접 확인한 후에 엔티티를 제대로 가져오는지 신뢰를 할 수 있기 때문에 각 계층이 엮여 있는 상태라고 할 수 있다.
해결책?
- 그렇다고 모든 객체를 미리 로딩할 수는 없다.
- 대안: 여러 상황에 따른 동일한 회원 조회 메서드를 여러 개 만들어 둔다.
- 문제: 다양한 상황을 고려한 너무 많은 메서드를 생성해야 한다.
memberDAO.getMember(); // Member만 조회 memberDAO.getMemberWithTeam(); // Member와 Team 조회 memberDAO.getMemberWithOrderWithDelivery(); // Member, Order, Delivery 조회
- 이렇게 SQL을 직접 다루면 계층형 아키텍처(Layered 아키텍처)에서 진정한 의미의 계층 분할이 어렵다.
- 물리적으로는 계층이 나누어져 있지만, 논리적으로는 굉장히 강결합되어 있다.
6. “비교하기” 에서의 차이
# 일반적인 SQL을 사용하는 경우
String memberId = "100";
Member member1 = memberDAO.getMember(memberId);
Member member2 = memberDAO.getMember(memberId);
member1 == member2; // 다르다!!!
class MemberDAO {
public Member getMember(String memberId) {
String sql = "SELECT * FROM MEMBER WHERE MEMBER_ID = ?";
...
// JDBC API, SQL 실행
return new Member(...);
}
}
- 식별자가 같아도 DAO의
getMember()에서- 각각에 대해서 SELECT Query를 날리고 (두 번 날림)
new Member()로 객체를 생성하기 때문에 당연히 다르다.
# 자바 컬렉션에서 조회하는 경우
String memberId = "100";
Member member1 = list.get(memberId);
Member member2 = list.get(memberId);
member1 == member2; // 같다!!! (참조값이 같다.)
- 식별자가 같을 때 컬렉션에서의 두 객체의 참조값은 같기 때문에 두 객체는 같다.
마무리
- 객체답게 모델링 할수록 매핑 작업만 늘어난다.
- 객체를 자바 컬렉션에 저장하고 불러오듯이 DB에 저장할 수는 없을까?
- 이 고민의 결과가 바로 JPA(Java Persistence API) 이다!!
관련된 Post
- JDBC, JPA/Hibernate, Mybatis의 차이에 대해 알고 싶으시면 JDBC, JPA/Hibernate, Mybatis의 차이를 참고하시기 바랍니다.
- ORM의 개념에 대해 알고 싶으시면 ORM이란을 참고하시기 바랍니다.
- JPA의 개념에 대해 알고 싶으시면 JPA란을 참고하시기 바랍니다.


